我们说说关于DeepSeek的几个误导性很强的坊间传闻。咱们先来个快问快答,然后再具体解释原因。
DeepSeek有5万张H100吗?
答:远没有那么多,主要由上一代卡和阉割版本的卡组成。DeepSeek训练成本600万美元,真有这么低吗?
答:看怎么算,最少是600万美元,但总花费可能已经有26亿美元了。即便没有蒸馏,DeepSeek的数据总是从GPT偷的吧?
答:可能有从GPT薅的羊毛,但也是数据公司薅的,不是DeepSeek薅的。计算卡的需求是不是减弱了?
答:不,反而增加了。为什么R1输出结果的时候会说自己是GPT?
答:主要因为薅羊毛过程中数据的污染,次要原因是互联网数据污染。R1是不是国运级别的成果?类似AI”珍珠港事件”?
答:不是,而且这些念头可能会摧毁DeepSeek。
好,咱们现在细说每一个。
1. DeepSeek有5万张H100吗?
这方面传言最夸张的是Scale AI公司的CEO亚历山大·王的说法。他在接受CNBC采访时说,DeepSeek有大约5万张H100,但因为有美国的出口管制,所以DeepSeek不能公开说。
他们的理由是,卡是从新加坡转手的。英伟达全球销售额的占比,在2023年之前新加坡只有9%,而2023年后达到了22%,成了英伟达全球第二大采购国,又因为新加坡和中国关系紧密,所以就猜测有大量H100是从新加坡流到中国的。
首先这个说法是没有证据的,其次是新加坡的增量有合理的解释,再次是新加坡的法规非常严格,几张卡规模的黑市可能存在,几万张的黑市存在的可能性不高。
比较靠谱的分析来自Semianalysis最新一篇对DeepSeek的深度分析报告。我把链接放在文稿中了。当然,今天已经有很多上万字的中文翻译版了,感兴趣可以逐字逐句看。我简要地说一下结论:
Semianalysis认为,DeepSeek一共6万张计算卡,其中A100、H800、H100各1万张,H20还有3万张。
咱们以H100为标准,假如它的算力值是100的话,其他几张卡的算力都是多少呢?A100是它的上一代,算力大约50;H800是H100的第一次阉割版本,算力60;H20是H100的第二次阉割版,算力15。之所以阉割两次,是因为美国前后两次出台芯片禁令,英伟达不得不配合禁令为中国生产阉割版计算卡。如果是5万张H100的话,算力应该是500万;而现在DeepSeek拥有6万张拼凑起来的计算卡,总算力是255万。
Semianalysis又是依据什么推算结果的呢?主要是四部分:
- 英伟达公布的H800、H20的产能数据,美国出口管制记录
- 服务器资本支出模型的推算
- 对DeepSeek技术文档的逆向工程推算模型需求的总算力
- 用DeepSeek的母公司幻方量化的投资动向估计硬件采购能力
当然,如果你要是半导体行业的高层,或者金融领域关注半导体领域投资的专业分析人士就会知道,Semianalysis是全球半导体和AI产业研究的顶级机构,所以它给出的分析结果参考价值非常高。
2. 训练成本600万美元,真有这么低吗?
这个要看把什么算作成本了。
600万美元的说法,来自DeepSeek自己公布的V3模型的预训练费用。其中包含100万美元的14.8Ttoken的数据费用,还有460万美元的H800 GPU运行费用。这个费用就是按照算力对应的GPU时长和市面上租赁H800 GPU每小时的费用相乘得到的。两者相加,是560万美元。但还有其他费用没有计入——V3基础模型训练完,做微调后让它成为R1模型,还需要额外的100万美元。所以把基础模型的预训练和微调成R1整个算上,就是660万美元;不算微调就是560万美元。这就是600万美元训练成本的来源。
但DeepSeek毕竟不是租用算力做的模型,而是自己买卡,自己搭建服务器,自己人员高薪待遇搞研究、搞训练,所以硬件成本和人力成本都要计入成本,这些才占大头。
具体花费多少呢?还是依据Semianalysis的分析:购买GPU需要7亿美元;搭建服务器需要的其他零件、CPU、存储系统、操作系统的各种软件、冷却系统,这些需要9亿美元;这四年的运营成本加在一起还有9.44亿美元。总计大约26亿美元。
当然,由于今后开发新模型还会继续用到这些硬件,所以26亿美元并不能当作R1模型的训练成本,而是多年以后的总成本。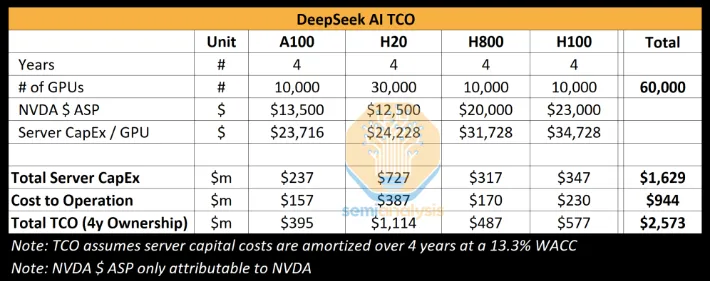
而如果对比类似规模的,比如Llama 3.1参数405B的模型,只谈训练费用的话,大约是6000万美元这个水平。而这个数字也比Meta此前在训练上花的上百亿美元要小的多得多。
尽管如此,DeepSeek预训练V3的600万美元,仍然比Llama 3.1的训练花销低了一个数量级。
我们尤其要注意的是,这个程度的降低依然是符合AI行业最近几年的大趋势的。对V3训练费用的降低,最恰当的形容是——在降低训练成本和推理成本上,DeepSeek首先做出了符合行业发展规律的突破。
Semianalysis也把性能达到特定分数的大语言模型的训练成本和推理成本,在最近几年的变化总结了出来。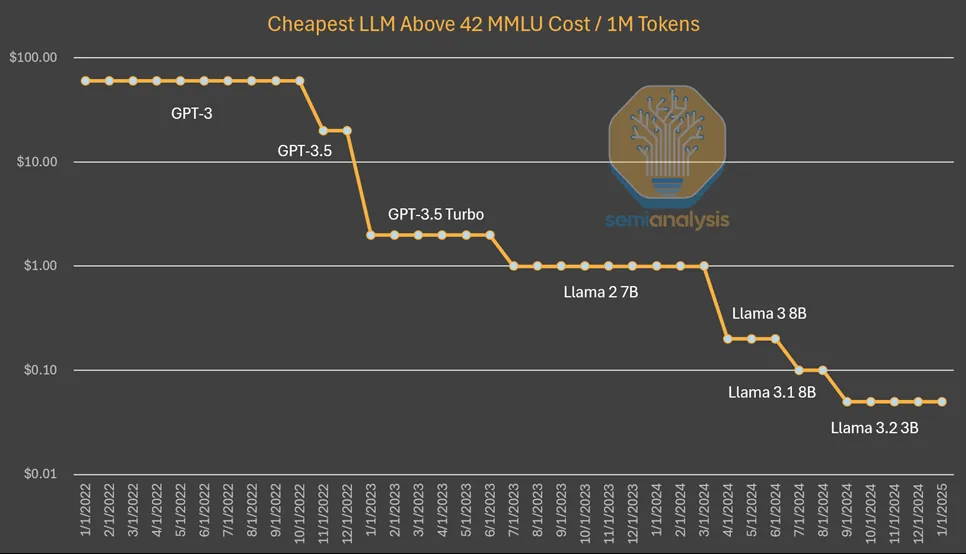
3. 即便没有蒸馏,DeepSeek的数据总是从GPT偷的吧?
首先,盗取数据的原始说法是微软说的:
2024年秋天,微软的安全员观察到,疑似与DeepSeek有关联的个人,使用了OpenAI的API接口窃取大量数据。
是不是真的盗取了,微软正在调查过程中,所以目前起码不能言之凿凿地说DeepSeek是偷的数据。
其次,训练大语言模型的公司,除了OpenAI作为第一个开创者,所有的数据都需要自己操办之外,后续加入的公司,数据一般都不是自己搞定的,而是从专门的数据公司买的。
比如这期开头提到的说DeepSeek有5万张H100的那个王姓美籍华人,他的公司就是专门卖数据的。整理清洗训练用数据已经是一个专业度很高的行业,今天都是由专门的公司负责的。所以微软也只能说,”与DeepSeek有关联的个人”而不是”DeepSeek”偷。
再次,相当多的初创公司和数据公司还真的是从OpenAI薅羊毛的,也就是搞数据的。
搞的方法也很普通。比如今天有很多给中国用户提供GPT服务的,这样用户就不用翻墙,也不用搞什么外国信用卡、外国电话号码去注册了。这些公司就是通过API接口,把用户的问题收集上来提交给GPT,然后等GPT回复后再转发给用户。他们作为中间环节,就可以把提问和回答保留下来,当作粗数据,再经过筛选和清洗,做成训练数据卖给大模型的开发者。
至于说DeepSeek买到的数据有没有哪个数据公司从OpenAI薅的羊毛呢,当然是有可能的,但最终结果如何,得看微软给出的证据是什么。
总之,薅羊毛是行业内的普遍现象。你输出结果越有逻辑,质量越好,每百万token价格越便宜,越有可能被盯上、被薅。以今天DeepSeek R1模型的性能和收费,大概率说,当下它也正在被疯狂地薅羊毛中。今后我们也会看到很多大模型自称是DeepSeek。
4. R1出现后,计算卡的需求是不是减弱了?
没有,反而增加了。
实际上,V3版推出后,H100的价格突然大幅上涨,后来R1发布后,又涨了一波,其实背后就是需求倍增。而在V3出现前的几个月,H100计算卡的价格是低迷的。
可能很多人要问,不是H100卖多少钱,英伟达已经定死了吗?怎么还有涨价、跌价?因为这是紧俏资源,巨头们都难以用原价买到,中间被黄牛囤积,所以才有涨跌。
为什么会涨价?因为V3和R1出现后,训练和推理成本大约下降了一个数量级,更多中小参与者也动念加入千卡、万卡的竞争中了。
比较讽刺的是,在R1模型发布后,市场上出现了一大波”今后不需要那么多计算卡””英伟达股价要跌了”的说法。我在1月27日知识城邦里专门讽刺了这种说法,举了一个例子:
我厂原来每月可以生产5000台笔记本,因为技术提升,现在每月可以生产10万台了,然后我厂就毅然决然地决定,每个月只开工半天,剩下20多天全歇业,把5000台生产出来不就完事了吗?别的厂就不会充分利用这些公开的技术突破,把月产量搞到10万、20万占领市场吗?
这不就是DeepSeek训练效率提高导致计算卡需求暴跌的奇怪论调吗?跌是因为英伟达的股价早就涨毛了,再涨下去,不用什么R1,夜深人静时一个脸盆掉地上,也一样可以被庄家利用,当作暴跌信号。
5. 为什么R1有时候会说自己是GPT?
其实这个问题在第3条刚说过,之前很多数据公司都瞄准了OpenAI薅羊毛,它们的训练数据如果清洗得不太干净,里面自然包含了很多原始出处的标签,别的模型拿这些数据训练,有时候就会回答自己是GPT。
一年前,很多国产大模型出现时,不少好事者就问大模型”你是谁”,差不多每个国产大模型都会说自己是GPT。当然,马斯克做的AI模型Grok在拒绝用户不合理问题时也会说,根据OpenAI的什么什么政策,我不能提供答案。谷歌的Gemini被中国人问到时也说过,自己的创始人是李彦宏。
你想,它们的中文训练材料从哪儿来的呢?说不定就是某个数据公司从文心一言里薅的羊毛。
以上是训练数据清洗不干净的造成的。这是最主要原因。
还有一个次要原因是,今天互联网上相当比例(超过10%)的内容是AI生成的,大模型从互联网上抓内容时,会偶然把这些带有公司标签的内容一起抓到,然后作为结果输出。
所以,某个大模型的输出说自己是另一个大模型,证明不了什么。
6. R1是不是国运级别的成果?
R1发布后,我在网上看到了好多版本的神吹,什么国运级别、AI珍珠港事件。凡是这么说的,或者觉得这么说有道理的,都和DeepSeek的领头人梁文峰对这个成果的理解大相径庭。
我们来看看梁文峰在接受采访时是怎么说的,他说:
我们的总结是,创新需要尽可能少的干预和管理,让每个人有自由发挥的空间和试错机会,创新都是自己生长出来的,不是可以安排的,更不是教出来的。创新就是昂贵且低效的,有时候伴随着浪费,所以经济发展到一定程度之后才能够出现创新,很穷的时候,或者不是创新驱动的行业,成本和效率非常关键,OpenAI也是烧了很多钱才出来的。
在被记者问到,你觉不觉得自己做的事情很疯狂时,他说:
我不知道我们做的事情是不是疯狂,但这个世界存在很多无法用逻辑解释的事,就像很多程序员,也是开源社区的疯狂贡献者,上了一天班很累了,还要去贡献代码。这里边会有一种精神奖赏,类似你徒步50公里,整个身体是瘫掉的,但精神很满足。不是所有人都能疯狂一辈子,但大部分人,在他年轻的那些年,可以完全没有功利目的地、投入地去做一件事。
对那些视DeepSeek为国运、AI武器、国与国之间斗争工具的想法,我要重复一下梁文峰的观点:伟大不能被计划。DeepSeek的创新被看到后,最好也不要被计划裹挟。你要真想看到创新,就不要去打扰人家,不要考核,不要自high。